MySQL has had replication for decades but the various options can be confusing. One social media post I read recently could be summarized with the statement 'there are too many good options but how do I know which is right for me?'
Cluster
Of all the words used in the computer related world, 'cluster' is the one that I wish we could have found a replacement for as the confusion over the word has created it's own cluster. Since MySQL has InnoDB Cluster and NDB cluster with other vendors using the word we end up with a lot of confusion. Add in clustered indexes and other non replication uses of the word to add more confusion. So which is what and where do we apply then for best performance.
MySQL Replication 101
The follow is an overview of MySQL replication offerings and the details are in the manual. And of course there are third party software that are not covered here that may have some utility for you. But so many folks are popping up on social media wanting a 'low cost five nines solution (99.999% up time)' solution or 'want to replicate terabytes of data to servers located around the world with automatic, sub-second fail over' that I thought it would be best to provide this overview.
Imagine you have two servers with exact copies of the same data on their hardware. One machine called the primary gets a query with an update/delete/modification and processes that query. Part of the processing is writing the query (or the results of the query) to a file that the other system, called the replica, copies to its hardware and then applies to its copy of the data. The end result is that once again both servers again have exact copies of the data.
Simple? Easy-peasy? Well then imagine adding in several thousand queries, network latency, differing work loads on the replica, and dozens of other issues that could impact performance. This imaginary situation provides a lot of queries and activities for both servers to juggle. Just like a busy short order cook, it is possible for orders to get lost or scheduled poorly which in turns leads to unhappy customers.
There are many ways to manage all this traffic, replication overhead, and administration.
Simple Replication
Replication enables data from one MySQL database server, known as a source or primary, to be copied to one or more MySQL database servers known as replicas. Replication is asynchronous by default but there is a semi-synchronous option. The replicas do not need to be connected permanently to receive updates from a source. And you can configure replication to copy all databases, selected databases, some databases of your choosing, or even selected tables within a database.
This is a great way to scale out read traffic, provide a copy of the data for use with backups, or provide a copy of the data for development/test/analytics. The traditional method replicating events from the source's binary log, and requires the log files and positions in them to be synchronized between the source and the replica. A newer method uses global transaction identifiers (GTIDs) and is transactional, therefore it does not require working with log files or positions within these files, which greatly simplifies many common replication tasks. Replication using GTIDs guarantees consistency between source and replica as long as all transactions committed on the source have also been applied on the replica. And GTID based replication is easier to automate.
MySQL supports three types of synchronization. The original type of synchronization is one-way, asynchronous replication, in which one server acts as the source and one or more other servers act as replicas. This is in contrast to the synchronous replication which is a characteristic of NDB Cluster which is covered later. MySQL 8.0's semisynchronous replication is in addition to the built-in asynchronous replication where a commit is performed on the source blocks before returning to the session that performed the transaction until at least one replica acknowledges that it has received and logged the events for the transaction
There are two core types of replication format, Statement Based Replication (SBR), which replicates entire SQL statements, and Row Based Replication (RBR), which replicates only the changed rows. You can also use a third variety, Mixed Based Replication (MBR). For the future it is best to row based replication which has the benefit of only sending the changes to the replicas instead of the query which can reduce traffic size.
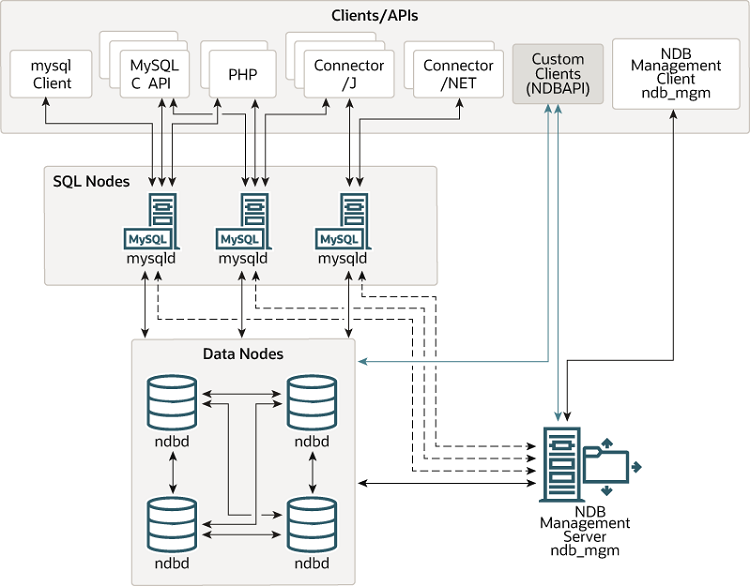
NDB Cluster
You cell phone provider probably uses NDB (Network Data Base) cluster to track your phone's position relative to the nearest cell tower. Wikipedia says MySQL Cluster is a technology providing shared-nothing clustering and auto-sharding for the MySQL database management system. It is designed to provide high availability and high throughput with low latency, while allowing for near linear scalability.[3] MySQL Cluster is implemented through the NDB or NDBCLUSTER storage engine for MySQL ("NDB" stands for Network Database). Note that they drop NDB from the entry.
An NDB Cluster consists of a set of computers, known as hosts, with each one running one or more processes. These processes, known as nodes, may include MySQL servers (for access to NDB data), data nodes (for storage of the data), one or more management servers, and possibly other specialized data access programs. To assure the shared-nothing standing you will need a lot of seemingly redundant hardware to avoid any one piece of being a point of failure. But if you want 99.999% down time you need to pay for the redundancy as you send your data between servers and data centers.
The data stored in the various data nodes for NDB Cluster can be mirrored. The cluster can handle failures of individual data nodes with no other impact than that a small number of transactions are aborted due to losing the transaction state, so write your applications so that they expect to handle transaction failure and retry commits if needed.
So other than the cost of the hardware, the cost of the networking gear, the salary for some smart folks to run operations, you really should get an enterprise subscription to get access to MySQL Enterprise Monitor to watch the various components.
NDB Cluster is missing some features found in the mainstream MySQL server such a index prefixes, savepoints/rollbacks are ignored, no generated columns, and statement based replication only among others.
This is your option if you need to be able to have less than 27 minutes of down time a year or really want synchronous replication.
MySQL InnoDB Cluster
MySQL InnoDB Cluster provides a complete high availability solution for MySQL servers. You use the MySQL Shell which includes the AdminAPI which enables you to easily configure and administer a group of at least three MySQL server instances to function as an InnoDB Cluster. Each MySQL server instance runs MySQL Group Replication, which provides the mechanism to replicate data within InnoDB Clusters, with built-in failover.

You application communicates through a copy of MySQL Router which is a lightweight Level 4 proxy. MySQL Router then forwards your queries to the cluster. In the above example we have two machines answering SELECT or read queries only and another server that can handle any query. The router decides who gets what, will load balance, and works with the cluster machines to avoid problems. If one of the machine goes offline, Router and the remaining machines will automatically handle the issue but once again make sure your application checks return codes so it can retry a commit.
InnoDB Cluster is built on MySQL Group Replication which provides a distributed state machine replication with strong coordination between servers. The servers coordinate themselves automatically when they are part of the same group. The group can operate in a single-primary mode with automatic primary election, where only one server accepts updates at a time or for more advanced users the group can be deployed in multi-primary mode, where all servers can accept updates, even if they are issued concurrently. This power comes at the expense of applications having to work around the limitations imposed by such deployments.
There is also a built-in group membership service that keeps the view of the group consistent and available for all servers at any given point in time. So servers can leave and join the group and the view is updated accordingly.
A really cool feature to InnoDB cluster is a plug-in that allows a new machine to be fully loaded with data from a donor machine by making it a clone of the donor. Very fast, low fuss, and a new machine joining the cluster is fully populated with data.
MySQL ReplicaSet
MySQL ReplicaSet is the newest of these offerings with many of the benefits of InnoDB cluster but mainly lacking automatic fail over if the primary stops for some reason. If you need the high availability, automatic fail over you want InnoDB cluster. But if you have simpler needs and do not occasionally mind promoting a secondary to primary, then you may want ReplicaSet.
ReplicaSet is MySQL 8.0 only, is GTID only, only supports Row Bases Replication, does not allow replication filters, and there is no automatic fail over. So if you needs are simpler this is a step up from generic replication and highly recommended due to the Clone plug-ins ability to bring a new node online so quickly.
Mixes
You can replicate from NDB or InnoDB Cluster to regular semi/async MySQL servers. So if you want the power of InnoDB cluster but want a safe server out of the clusters for backups or analytics.
So What Do I Choose?
This depends on your needs. Ferraris, I am told, are wonderful cars but they are not made to be dump trucks, fire engines, or low cost grocery getters.
If you can live with the limitations of NDB need to replicate a) between data centers, b) have minimal down time, c) and have the budget to support a&b then I recommend NDB cluster. I do know of folks replication between data centers with InnoDB Cluster or generic replication too but NDB was designed to do this all with the minimal down time.
Need high availability with automatic fail over? InnoDB cluster.
Or is your replication need not as sophisticated? Then I recommend ReplicaSET.